KTH BigDataBase and Enabling Data Sharing
Design och utveckling av en big data databas som samlar data från andra befintliga databaser – som i sin tur hanterar sensordata från olika verksamheter. Databasen ska även hantera Internet of Things och artificiell intelligens-tekniker som maskininlärning. Med databasen tillgängliggörs data som kan synliggöra innovation inom bygg- och fastighetssektorerna på nya sätt.
Bakgrund
Intresset att förlägga forskning och utveckling i faktiska miljöer är stort och det finns ett starkt behov från industrin och akademin att tillgängliggöra städer, byggnader och verksamheter för forskning, tester och utbildning. Ofta finns städer och byggnader med sensorer och uppkopplade enheter tillgängligt, men strukturer, rutiner och system för effektiv och säker hantering av data och information kopplat till data saknas. Företag och organisationer har ofta även stora dataset lagrade, men relevanta lagliga strukturer för hur data kan och bör användas saknas oftast. För att kunna nyttja data och förstå användningen av städer, byggnader och verksamheter bättre behövs en öppen och transparent datahantering: en öppen databas.
Med uppbyggandet av en öppen databas följer även frågor kring integritet och datasäkerhet. KTH Live-In Lab (LIL) har redan genomfört ett projekt kring GDPR och smarta byggnader i samverkan med rättsinformatik på Stockholms Universitet (SU), och ett fortsättningsprojekt kring etikprövning och smarta byggnader är pågående. Dessutom pågår samtal med SU kring en nationell forskningsdatabas.
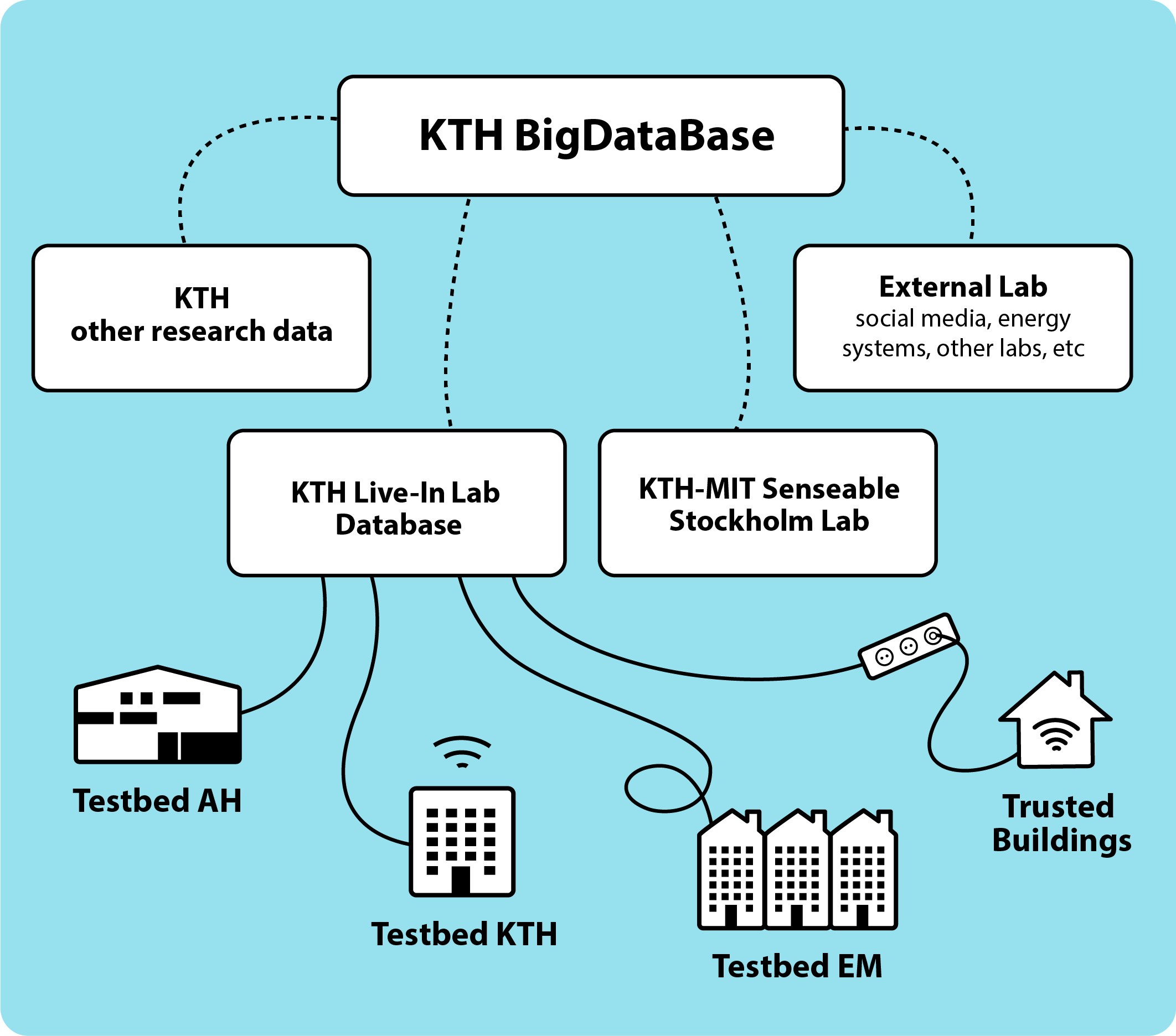
Många forskargrupper och lärare saknar i dagsläget data för att extrahera information vilket gör att forskning och utbildning ofta hänvisas till simuleringar baserade på fabricerade dataset för test och verifiering av modeller eller prototyper. KTH BigDataBase kommer tillhandahålla både databas och realtidsdata till forskargrupper vilka tidigare inte haft tillgång till detta. Inte nog med det, BigDataBase kommer även tillhandahålla sakkunskap om hur datan har genererats, vilket ökar validiteten för framtagna forskningsresultat.
Projektbeskrivning
Projektet syftar till att kravställa och implementera en databas som på ett skalbart sätt hanterar stora datamängder med initialt fokus på fastighets- och användardata samt data från städer. Det handlar om att designa och utveckla en big data databas som samlar data från andra befintliga databaser som, i sin tur, hanterar sensordata i olika verksamheter. Databasen ska även hantera Internet of Things och AI-tekniker, såsom maskininlärning, för att tillhandahålla data till olika intressentgrupper, forskare, studenter, samt små och medelstora företag och fastighetsägare så att de kan möjliggöra innovationer och därmed stärka Sveriges konkurrenskraft.
Den underliggande hypotesen med databasen är att innovation i bygg- och fastighetssektorerna kan synliggöras på helt nya sätt och till nya grupper genom att visa användbarheten av fastighetsrelaterade data, till exempel öka förståelsen hos både förvaltare och boende för verklig drift av byggnader.
Mål
- Projektet ska ta fram en design för databasen och förslag på strukturer för informationshantering, informationsspridning och samverkan.
- Databasen ska kunna ta hand om data från både KTH Live-In Lab och andra byggnader som är tänkta att bli delar av KTH Live-In Lab:s infrastruktur.
- Data ska på ett säkert och pålitligt sätt kunna göras tillgänglig till alla olika inblandade aktörer, från studenter och forskare till företag och myndigheter.
- Problemställningar som datakvalitet, skalbarhet och kommunikationshastighet ska tas i beaktning och undersökas noggrant.
- Projektet ska förutom en databasprototyp även resultera i riktlinjer, kravspecifikationer, metoder och guider för hur olika aktörer som vill hantera stora mängder data och information kan arbeta med lagring, tillgängliggörande och informationsspridning.
Syfte och mål
Projektet syftar till att ta fram strukturer för informationshantering och spridning av data från främst verksamheter inom KTH. Dessa strukturer ska testas genom att bygga upp en fullskalig databas för KTH Live-In Lab och KTH-MIT Senseable Stockholm Lab. Strukturerna ska vara generiska och kunna användas för framtagande av databaser för andra sorters data. Vidare ska data på ett säkert och pålitligt sätt kunna göras tillgänglig för olika aktörer. Problemställningar som datakvalitet, skalbarhet och kommunikationshastighet ska tas i beaktning.
Målet med projektet är en skalbar och öppen databasprototyp som stödjer användarnas behov, samt samlar och tillhandahåller data och information. Ett långsiktigt mål är att genom metoder som maskininlärning kunna modellera och prediktera skeenden och därmed automatisera processer inom nya områden genom sammanlänkning av data från tidigare skilda dataset/verksamheter, samt att förbättra teknik (sensorbeteenden, produkter och tjänster), metoder och beteendemönster.
Genomförande
Efter att ha gått igenom en del av det aktuella utbudet av större och mer omfattande lösningar som kan möta Live-in Labs behov, men också möta behoven för KTH i stort, har vi kommit fram till att en databaslösning baserad på den öppna plattformen Hadoop skulle vara lämplig att testköra för syftet.
Hadoop används och vidareutvecklas idag av flera stora aktörer, som Google och British Royal Mail.
Då denna lösning, i big data och mångsidighet, är av modell större i projektläggning och karaktär, så kommer en lösning att tas fram och utvärderas i etapper varpå vi efter hand och vid behov utökar dess funktionalitet i takt med att Live-in Lab-projektet växer.
Use cases som vi utgått ifrån
- ”Som student vill jag analysera data (eller snarare att något analyserar data åt mig!) för att förbättra mina studieförutsättningar.”
Detta kan vara data som kommer från olika källor och lever ostrukturerat i KTHBD. - ”Som forskare vill jag kunna få access till rådata (realtids och historisk) för att kunna utveckla nya tjänster."
Detta kan vara data som kommer från olika källor och lever ostrukturerat i KTHBD. - ”Som drift/operatör vill jag kunna skapa enkla diagram, aggregering av datasets, avpersonifiera data för att delge data på hemsida."
Detta kan vara data som kommer från olika källor och lever ostrukturerat i KTHBD. - ”Som lärare vill jag kunna hämta avpersonifierad data för att kunna skapa case studies/projekt kring byggnader och system."
Detta kan vara data som kommer från olika källor och lever ostrukturerat i KTHBD. - ”Som forskare vill jag att LIL:s data ska tillgängliggöras så att jag kan analysera och utforska värdeskapande innovativa tjänster.”
- ”Som forskare vill jag att LIL:s system och installationer i bostäderna ska tillgängliggöras så att jag kan involvera hyresgästerna att testa nya innovativa produkter och tjänster.”
- ”Som finansiär vill jag att forskningsprojekt som bedrivs i LIL ska publiceras så att jag kan ta del av metod och resultat för att nå bättre insikt och kunskap.”
- ”Som finansiär vill jag kunna initiera forsknings-och utvecklingsprojekt i LIL så att jag kan agera som en involverad och drivande partner.”
- ”Som finansiär vill jag att forskningsprojekt som bedrivs i LIL ska generera värdeskapande kommersialiseringsbara lösningar så att jag kan agera som en affärspartner.”
- ”Som forskare vill jag använda … information om invånarna (ålder, aktivitet...) och information om de olika platserna (utomhustemperatur, ljusförhållanden...) för att reflektera över mina resultat.”
- “Som startup inom sensor-utveckling vill jag kunna verifiera rådata från egen-utvecklade sensorer mot befintlig kontrolldata från KTH LIL, samt kunna träna matematiska modeller för att extrapolera ny data.”
- ”Som forskare vill jag kunna installera nya sensorer och system och få värden från dessa in till samma system som befintliga sensorer/system.”
Med ovanstående behov som utgångspunkt är vi övertygade att en big data-lösning (KTHBD) kommer täcka de behov som finns på KTH idag och framöver.


